 Chinese
Chinese English
English
- more领导致辞 / Speech
-

我新利(中国)自成立以来,不断谋求新的发展,承接了国内多项大型的工程 ,取得了多项荣誉称号,积累了丰富的施工经验,掌握了各种新型施工技术。多年来,我新利(中国)恪守“以人为本、质量第一、客户至上”的服务宗旨,遵循“优质、高效、团结、奉献”精神。为适应于市场,服务于市场,经过国家批准福建正天军正建设工程集团有限新利(中国)已接收新疆、重庆、青岛土石方工程以及国家一系列重点工程。
工程案例
Project case

桥梁及医院和学校
2016年至今与浙江沧海集团在湖州投资98亿元人民币,兴建大型市政桥梁,道路及绿化,医院…

温州瓯海新区市政一期
2015年3月福建正天盛世实业有限新利(中国)与浙江沧海集团投资建设温州瓯海新区市政一期工程三…

水库及城市环网
2013年6月福建正天盛世实业有限新利(中国)与浙江沧海集团投资了毛家坪周公宅(皎口)水库引水…

横山水库及景观园林
2012年10月福建正天矿业有限新利(中国)与浙江沧海集团共同投资并开发建设了位于横山水库加固改…
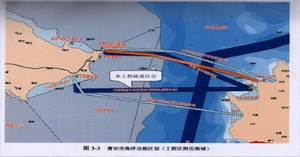
沿海中部莆田兴化湾
2008年10月20日莆田市港口管理局经研究,批准福建正天航道工程有限新利(中国)开展莆田石城国家…

园林及绿化水景
2008年上半年间与浙江沧海集团形成战略合作并投资承建了位于杭州的西溪湿地国家公园一期…